Combinando tecnología y metodología en scenarios de Health Big Data Analytics
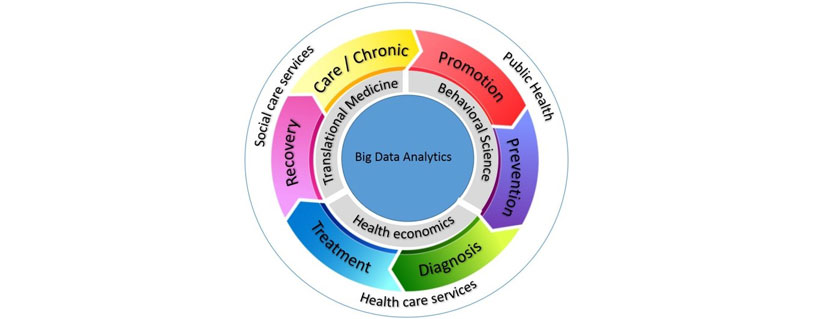
Las organizaciones de salud están recopilando datos de una amplia gama de fuentes cada día con más velocidad. El análisis de esta vasta cantidad y variedad de datos crea nuevas oportunidades para ofrecer servicios de salud y atención social modernos y personalizados. Healthcare analytics proporciona métodos y procesos para extraer y transformar datos médicos y asistenciales en nuevo conocimiento para apoyar decisiones eficientes y efectivas en el cuidado de la salud. Sin embargo, todavía no hay un enfoque metodológico específico que conduzca el proceso completo de diseño y construcción, desde los datos crudos hasta la activación eficaz del conocimiento en las rutinas diarias médicas. Nuestro enfoque se centra en las áreas y actividades clásicas de salud que combinan 1) nuevos paradigmas tecnológicos desarrollados en el ámbito de Data Analytics y Big Data y 2) nuevos enfoques metodológicos de la medicina traslacional, la economía de la salud y las ciencias del comportamiento. El objetivo principal de la aplicación de health data analytics junto con otras ramas del conocimiento como las ciencias sociales y del comportamiento, es desarrollar un marco analítico innovador que contribuya a la mejora en todo el continuo de salud (promoción, Recuperación y atención / crónica).
Las organizaciones de salud se enfrentan a un nuevo escenario donde las herramientas analíticas deben acomodar tanto el «Business Intelligence» tradicional como los nuevos enfoques de análisis de datos. Esto impone abordar desafíos tecnológicos y metodológicos importantes. Estos desafíos son la fuerza que impulsa el diseño del marco analítico bajo el prisma de la metodología esquematizada en la figura anterior. Desde esta perspectiva, en lugar de definir lo que es Big Data en términos de V s, proponemos hacerlo sobre la base de las soluciones tecnológicas que apoyan a las nuevas necesidades de negocio, como 1) bases de datos NoSQL (no sólo SQL), 2) almacenamiento distribuido y computación distribuida 3) Machine Learning distribuido y 4) Tecnologías de virtualización en sus diferentes grados (hipervisores, contenedores Linux y contenedores de aplicaciones).
El marco analítico que soporta los objetivos de la cátedra UOC-BSA, estructura las diferentes soluciones y enfoques de las cuatro líneas anteriores, en una plataforma lógica de cuatro capas, 1) La capa de fuentes y de almacenamiento, 2) La capa de datos, 3) la capa cognitiva y 4) la capa de metadatos, así como los conectores y las soluciones de transferencia de datos entre capas.
En vista de los diferentes requerimientos de cada proyecto analítico específico, la plataforma tecnológica a implementar debe adaptarse a diferentes escenarios, cubriendo tanto los enfoques analíticos más tradicionales como entornos más innovadores donde se necesitan tecnologías asociadas a Big Data Analytics. En este contexto, se deben tomar varias decisiones respecto al enfoque de almacenamiento de datos, diseño distribuido, selección de herramientas y modelos analíticos. Para ello, consideramos un conjunto de directrices de diseño que impulsan las decisiones técnicas y estructurales sobre la construcción del framework tecnológico (soporte heterogéneo de datos, agilidad y flexibilidad, apoyo a la gestión de metadatos, estabilidad de soluciones, uso de estándares, etc.).
Siguiendo estas premisas es como hemos desarrollado el enfoque metodológico, la estructura técnica y las directrices de diseño necesarias para desarrollar el laboratorio de datos que apoya los proyectos analíticos desarrollados en el contexto de la cátedra.
